Seneca kann Daten aus einer von Ihnen zu bestimmenden Datei in die Knoten Ihrer Struktur importieren (zulässige Formate: Excel, Datenbank, CSV oder XML).
Im Folgenden werden wir Ihnen einen Excel-Import anhand einer Bilanz vorstellen und die Unterschiede der anderen Datenformate ansprechen. Abschließend gibt es eine gesonderte, detaillierte Beschreibung der fünf verschiedenen Importlogiken.
Kontenrahmen-Import
Seneca kann den Kontenrahmen Ihrer Mandanten spielend einfach über einen Import ändern.
– Wählen Sie eine Excel-Datei aus, in der Sie die Kontenbereiche pflegen.
– Wählen Sie im Importziel nur die Knoten «GuV» und «Importbilanz» aus.
– Wählen Sie einen eindeutigen Schlüssel für den Import (die Strukturen und auch die Excel-Datei beinhalten diese).
– Klicken Sie nun auf «Kontenbereich» und starten Sie den Import.
– Alle bestehenden Kontenbereiche haben sich nun geändert.
Hierarchischer Import
Für den hierarchischen Import in Seneca benötigt man für jede Hierarchie und jeden Knoten einen Schlüssel. Positionen ohne Schlüssel werden nicht berücksichtigt.
Sie haben die Möglichkeit, die Datei von Seneca bearbeiten zu lassen. Dazu wählt man im neuen Importschritt «Umwandeln der Quelle» die Spalten aus, die man benötigt.
Seneca konvertiert anschließend die Datei, sodass die neuen Spalten als Schlüssel im Importabschnitt «Schlüssel» verwendet werden können.
Import aus Excel (anhand einer Bilanz):
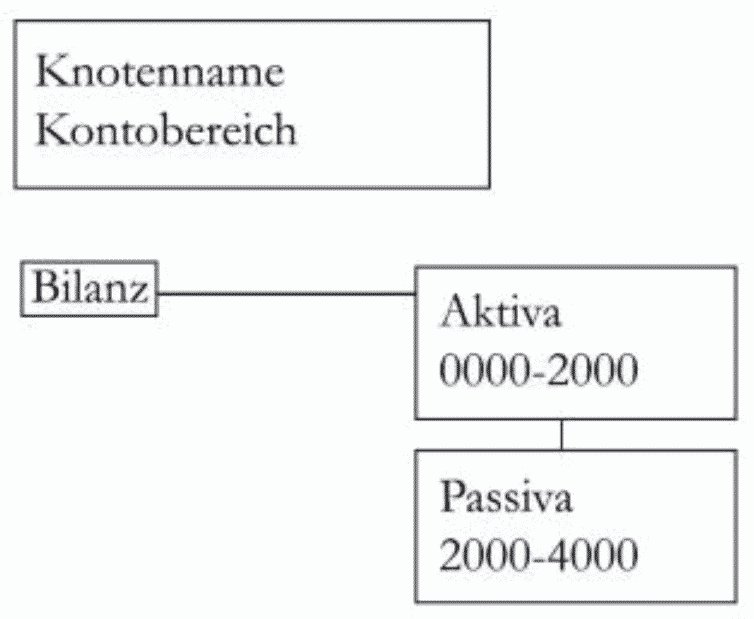
Für dieses Beispiel bauen Sie sich bitte eine Struktur mit folgendem Aussehen auf. Den Kontenbereich können Sie in den Knoteneigenschaften angeben.
1. Wählen Sie «Excel» als Importvariante aus.
2. Laden Sie die gewünschte Datei von Ihrem PC oder dem von Seneca zur Verfügung gestellten FTP-Onlinelaufwerk hoch.
3. Wählen Sie das Blatt mit den relevanten Daten aus.
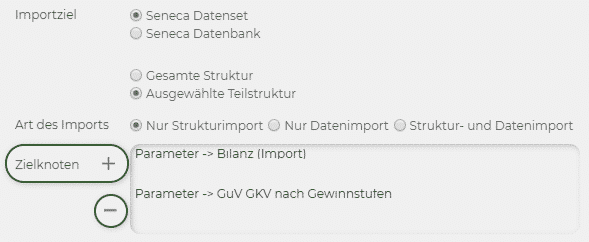
4. Hier können Sie Teilimporte hinzufügen. Sie können mit derselben Datenquelle für den Import, eine weitere oder auch mehrere Importlogiken für den mehrfachen Import der Datenquelle in die Zielstruktur verwenden.
5. Als Importziel können Sie entweder die gesamte Struktur oder eine Teilstruktur spezifizieren. Die Teilstruktur können Sie über das + Symbol hinzufügen und über das – wieder löschen. Sie können auch wählen, ob der Import in Ihre Seneca-Struktur (Seneca) oder in Ihre Datenbank in Seneca (Seneca Datenbank) erfolgen soll.
6. Für dieses Beispiel sollten Sie die erste Importlogik auswählen. Eine detaillierte Anleitung zu allen fünf Importlogiken finden Sie unter «Importlogiken».
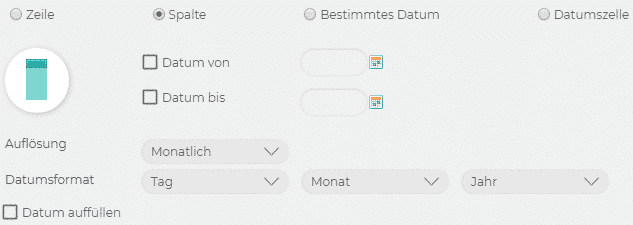
7. Als nächstes legen Sie das Datum fest. Damit Seneca dieses erkennen kann, muss das Datum im ExcelDokument als Datum formatiert sein. Wählen Sie aus, ob die Daten in einer Zeile oder Spalte im Dokument stehen. Wenn die Daten lediglich in ein bestimmtes Datum importiert werden sollen, wählen Sie «Bestimmtes Datum».
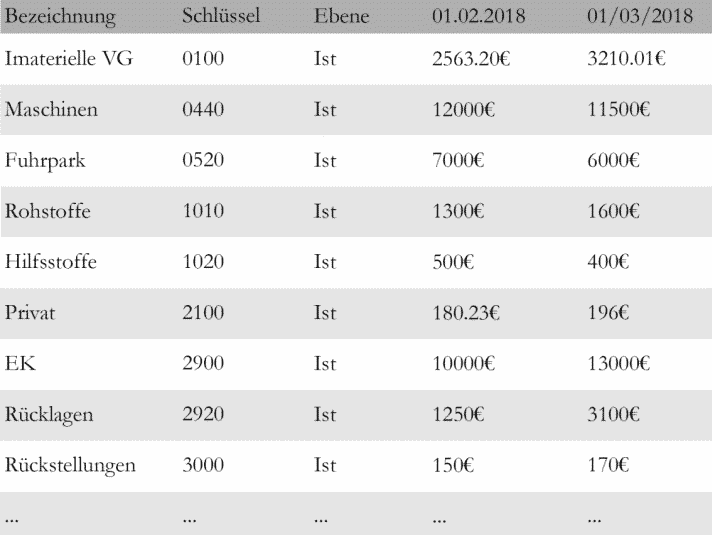
Anschließend markieren Sie den Bereich in der Vorschau, indem Sie das Feld anklicken und dann in das erste Datum in der Vorschau klicken. Die genaue Reihenfolge des Datum-Formats soll eingetragen werden, z.B.: Tag, Monat, Jahr oder Jahr, Monat, Tag. Hier ein Beispiel für die Tabelle:
8. Nun legen Sie den Schlüssel und die Bezeichnung fest. Durch den Schlüssel erkennt Seneca, hinter welchem Knoten der neue Knoten angelegt werden soll. Die Bezeichnung legt fest, wie der Knoten später in Seneca benannt wird.
Beispiel: Hilfsstoffe hat den Schlüssel 1020, der im Kontenbereich vom Knoten Aktiva liegt → Hilfsstoffe wird nach erfolgreichem Import hinter dem Knoten Aktiva mit dem Namen, der unter Bezeichnung steht, angelegt.
Mit einem Häkchen bei «Schlüssel ausfüllen» werden die fehlenden Konten in der Reihenfolge ergänzt. Knoten, die in der Struktur nicht zu finden sind, könnten einem gezielten Knoten zugeordnet werden. Selektieren Sie den Zielknoten mit Hilfe von «nicht zugeordnete Schlüssel».
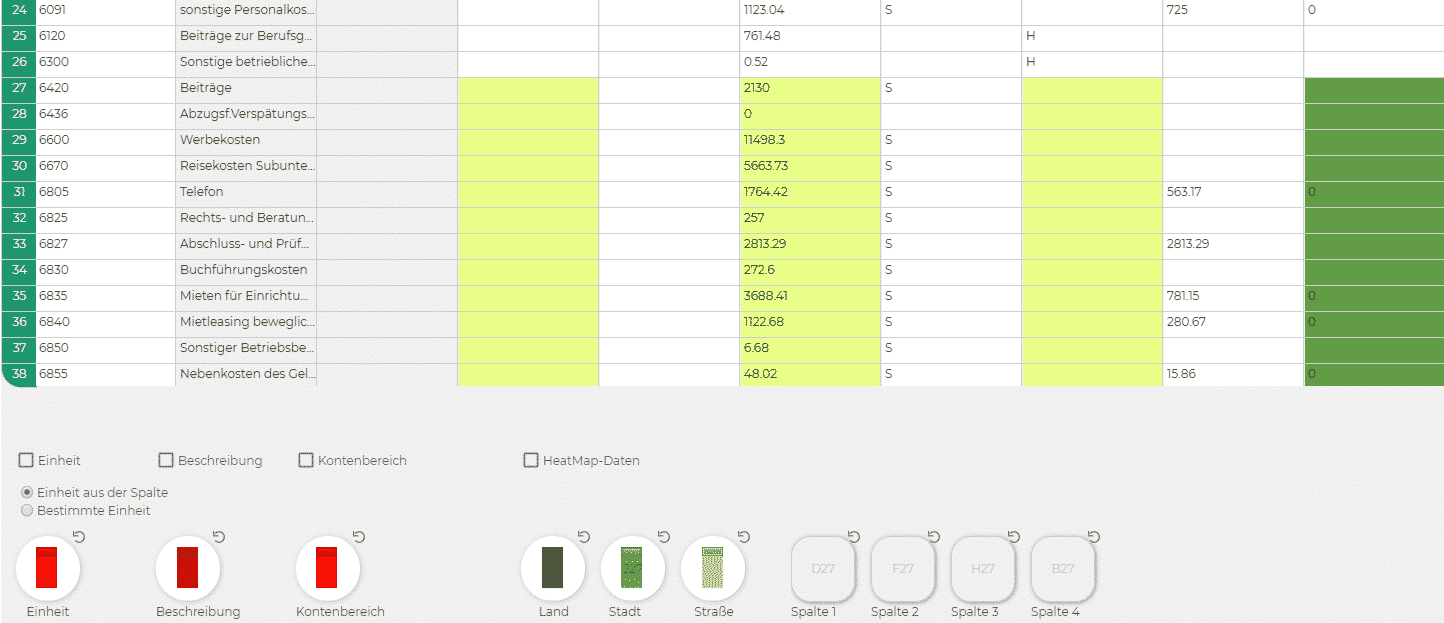
9. Unter «Knoteneigenschaften» können Sie Adressen in Ihre Knoten importieren sowie Einheiten beschreiben. Wenn Sie unter Importziel «Seneca» ausgewählt haben, erscheinen folgender Balken (siehe Abb.).
Wählen Sie hier in der Excel-Vorschau die Spalten aus, die Land, Stadt und Adresse enthalten. Die Adressen werden dann in die Knoten importiert. Wenn Sie unter Importziel «Seneca Datenbank» ausgewählt haben, erscheinen folgende Balken (siehe Abb.).
Die gelben Balken stehen für die Spalten, die Sie in die neue SQL-Datei implementieren können. Im Datenbank-Manager haben Sie dann eine Einsicht in die generierten Tabellen. Hier können Sie die SQL-Abfrage vorbereiten.
10.Anschließend geben Sie an, in welche Ebene die Daten importiert werden. Dafür gibt es verschiedene Möglichkeiten:
Wenn Seneca für Sie die Zuteilung automatisch vornehmen soll, ist es wichtig, dass die Ebenenbezeichnungen im Dokument und in der Struktur übereinstimmen. Dazu klicken Sie in das runde Feld und wählen die Spalte aus, in der die Ebenenbezeichnungen stehen.
Sie können die Ebenen jedoch auch individuell zuordnen. Klicken Sie dazu in eins der Felder aus dem nebenstehenden Bereich und markieren Sie im Excel-Dokument den Namen der Ebene. Alle Werte aus dem Excel-Dokument werden dann der entsprechenden Ebene zugeordnet.
Sie können die Daten auch alle in eine spezifische, von Ihnen zu bestimmende Ebene importieren. Markieren Sie dazu «Bestimmte Ebene» und wählen die gewünschte Ebene aus.
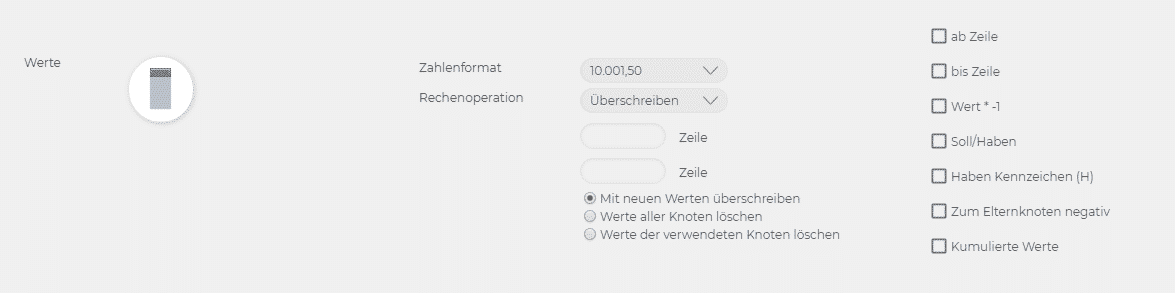
11. Nun wählen Sie noch den Datenbereich aus. Klicken Sie dazu in das runde Feld und wählen die obere linke Ecke des Datenbereichs in der Vorschau aus. Geben Sie noch das korrekte Nummernformat an, in dem die Daten formatiert sind und bestimmen Sie eine Rechenoperation.
Falls Sie Ihren Datenimportbereich beschränken wollen, können Sie die relevanten Zeilen bestimmen. Außerdem können Sie alle Werte mit (-1) durchmultiplizieren. Dies kann beispielsweise für den Import in eine GuV nützlich sein.
Falls Sie Soll- und Habenwerte in Ihrer Excel-Datei haben, können Sie diese ebenfalls über das Quadrat markieren. Seneca errechnet Ihnen automatisch den richtigen Wert (Soll-Haben) und speichert ihn in den Knoten.
Weitere Einstellungen:
– «Nur mit neuen Werten überschreiben»: die alten Werte werden mit den importierten Werten überschrieben. Importierte Nullen zählen nicht dazu.
– «Den Wert aller Knoten löschen»: Die Werte aller Knoten, ausgehend vom ausgewählten Knoten, werden gelöscht. Danach wird der Import in die leere Struktur durchgeführt.
– «Nur den Wert der verwendeten Knoten löschen»: Löscht die Werte der Knoten, die vom Import betroffen sind. Andere Knoten bleiben unberührt.
12. Zu guter Letzt die Ausführung: Wenn Sie den Import abschließen wollen, klicken Sie auf «Alles importieren».
Unter «Speichern» haben Sie die Möglichkeit, den Import abzuspeichern. Dies bietet sich an, wenn Sie den Import häufiger durchführen müssen und als Ressource im Unternehmen schnell darauf zugreifen möchten.
Nun haben Sie den Import erfolgreich abgeschlossen! Die Daten Ihres Excel-Dokuments sind damit in Ihre Struktur eingespeist. Achten Sie darauf, dass Ihr Excel-Dokument ähnlich dem Beispiel aufgebaut ist.
Datenimport mit einem .csv-Dokument
CSV steht für comma-seperated values. Ein .csv-Dokument ist mit einem Excel-Dokument ohne Raster vergleichbar, in dem die Trennung über ein Trennzeichen erfolgt. Bis auf den Schritt «CSV» gleicht dieser Import deshalb dem Excel-Import.
In diesem Schritt müssen Sie das Trennsymbol markieren, durch das die einzelnen Werte voneinander getrennt werden, und falls der Text durch besondere Zeichen gekennzeichnet ist, dort ebenfalls eine Auswahl treffen. Zum weiteren Verfahren bitte im Kapitel Import mit Excel nachschauen.
Datenimport mit einer Datenbank
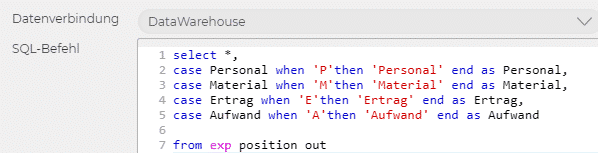
Der Datenimport mit einer Datenbank ähnelt dem Beispiel der Bilanz. Es kommt lediglich der Schritt «ODBC» hinzu. Bei diesem Schritt wählen Sie eine vorhandene Datenbank des Unternehmens aus und geben einen SQL-Befehl ein, um die gewünschte Tabelle zu erhalten. Der Rest des Imports geschieht nach dem Muster der Bilanz.
Datenimport mit einem XML-Dokument
Zur Datensicherung können Sie Teilstrukturen oder die Gesamtstruktur aus Ihrem Datensatz exportieren und diese bei Bedarf wieder importieren. So können Sie sicherstellen, dass Ihre Daten erhalten bleiben. Wie beim Import eines csv-Dokuments, gleicht auch der Import einer XML-Datei dem einer Excel-Datei. Der Unterschied liegt im Schritt XML-Optionen
Dort wählen Sie lediglich Ihre Zeitansicht und die Rechenoperation aus und fahren danach wie gehabt fort.
Importlogiken
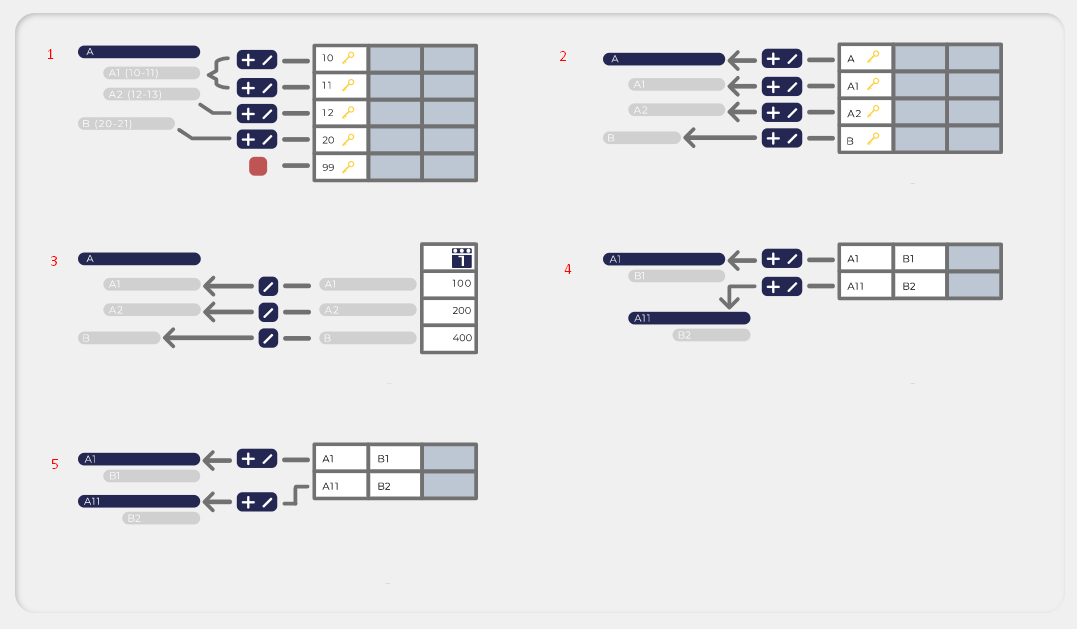
Im vierten Schritt eines Datenimports wählen Sie zunächst eine Importlogik wählen. Die Seneca Controlling Software verfügt über fünf verschiedene Importlogiken. Grundsätzlich ist zu sagen, dass die Importe immer einen Schlüssel benötigen.
1. Bei dieser Importlogik importiert Seneca Daten in Ihre Struktur gemäß der vorher angegebenen Konten. Rufen Sie sich das Beispiel der Bilanz aus dem Excel-Import in Erinnerung. Die Aktiva erhielten dort den Bereich 0000 – 2000 und die Passiva den Kontenbereich 2000 – 4000. Dies können Sie unter den Knoteneigenschaften bestimmen:
Beim Import wird von Seneca überprüft, ob das Konto der zu importierenden Position im vorher angegebenen Bereich liegt. Wenn ja, wird hinter dem Knoten mit dem Kontenbereich ein neuer Knoten mit der angegebenen Bezeichnung angelegt und die Daten werden in diesen importiert.
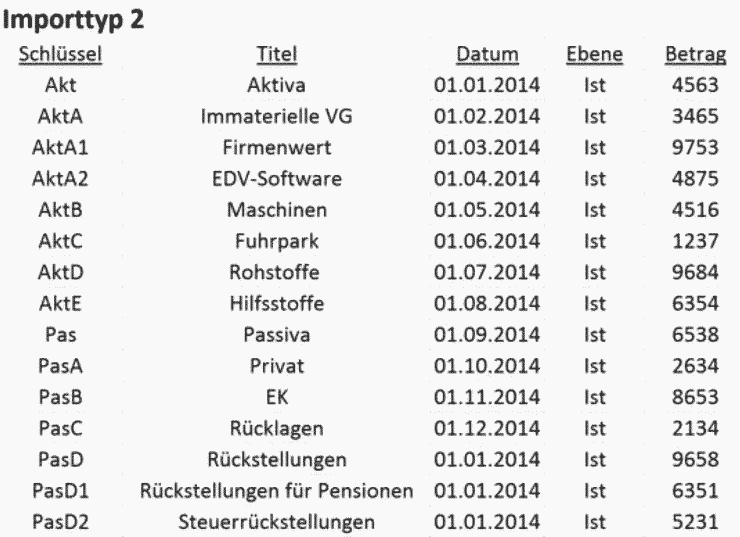
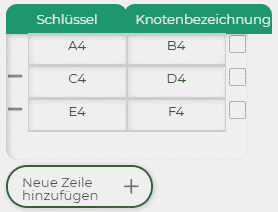
2. Bei dieser Importlogik wird ein kombinierter Schlüssel aus dem Excel-Dokument von Seneca automatisch aufgespalten und in verschiedene Hierarchieebenen aufgeteilt. Beispiel: Folgendes Excel-Dokument erzeugt mit der zweiten Importlogik folgendes Ergebnis (siehe Abb. links).
Wie Sie sehen, hat Seneca drei Hierarchieebenen erstellt. Das liegt am Schlüssel. Durch die Erweiterung von «Akt» um ein «A» erkennt Seneca, dass eine neue Ebene erstellt werden muss. Die Erweiterung um eine «1» erzeugt erneut eine weitere Ebene. Auf diese Weise können Sie sehr einfach sehr und schnell größere Strukturen mit einem Import aufbauen.
3. Bei der dritten Import-Variante geht es darum, dass Sie vorher aus Seneca exportierte Daten nun wieder importieren können. Beim Export Ihrer Daten aus der Struktur erstellt Ihnen Seneca unter «Node-Identifier» eine einmalig vergebene Knoten-ID. Beim erneuten Import können Sie dann als Schlüssel die KnotenID angeben.
4. Bei dieser Importlogik handelt es sich um einen Hybrid aus der fünften und zweiten Variante. Die Einteilung in Hierarchieebenen wird hier, trotz Angabe der verschiedenen Schlüssel mit Bezeichnungen, automatisch vorgenommen und zwar nach dem Prinzip der zweiten Importlogik.
Das folgende Beispiel verdeutlicht das Prinzip: Diese Excel-Tabelle als Grundlage für den Import nach Logik 4, ergibt mit folgenden Schlüsseln das folgende Ergebnis (siehe Abb. links).
Wie Sie sehen können, wurden «Birne», «Banane» und «Kokosnuss» eine Hierarchieebene tiefer angelegt als «Apple». Das liegt an den verwendeten Schlüsseln, die Sie dem Excel-Dokument entnehmen können. Durch die Erweiterung des Schlüssels um eine 1(2,3) legt Seneca die Knoten automatisch eine Hierarchieebene tiefer an.
5. Mit dieser Logik importieren Sie eine genau definierte Struktur, inklusive Unterebenen und Ihrer Daten. Der Unterschied zur ersten Importvariante liegt darin, dass Sie mehrere Schlüssel angeben können, die verschiedene Hierarchieebenen erstellen. Wir zeigen Ihnen nun ein Beispiel, dass dieses Prinzip verdeutlicht:
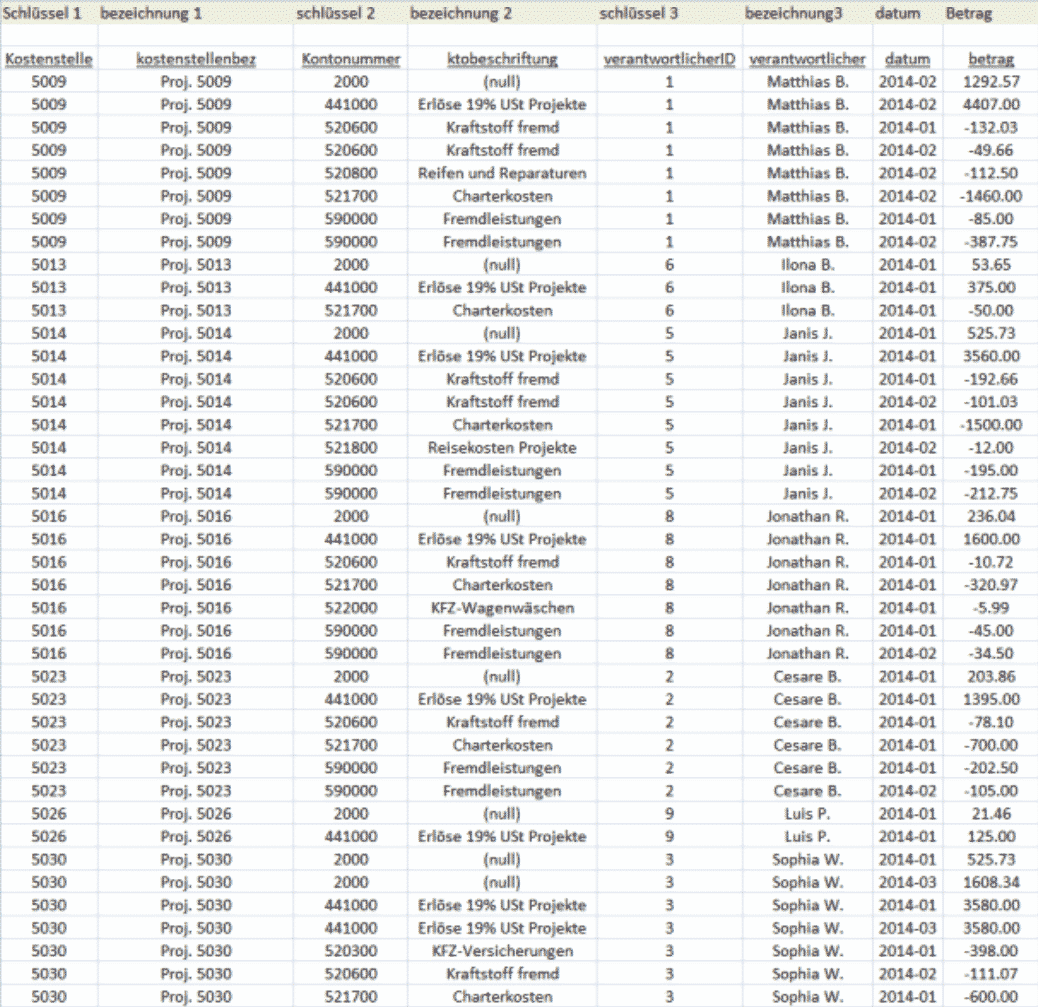
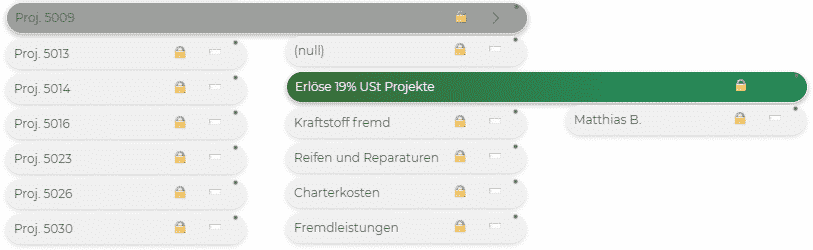
Lassen Sie uns annehmen, Sie wollen einen Überblick über die Profitabilität Ihrer Projekte erhalten. Dann sollte auf der 1. Hierarchieebene das Projekt stehen. Danach wollen Sie die verschiedenen Konten des Projektes sehen und zu guter Letzt den Verantwortlichen des Projektes nach Konten sortiert.
Wählen Sie im Excel Import die Variante 5. Behandeln Sie alles andere wie im Beispiel der Bilanz.
Beim «Schlüssel» sehen Sie nun, dass die Möglichkeit besteht, mehrere hinzuzufügen. Wählen Sie also als ersten Schlüssel die Spalte A aus und als Bezeichnung die Spalte B. Für die Konten wählen Sie als Schlüssel die Spalte C aus und für die Bezeichnung die Spalte D. Die VerantwortlichenID der Spalte E ist Ihr Schlüssel und der Name Ihre Bezeichnung.
Wenn Sie nun den Import wie gehabt durchführen, erstellt Ihnen Seneca eine Struktur die folgendermaßen aussieht (siehe Abb. rechts).